Open Source Inference at Full Throttle: Exploring TGI and vLLM

Large language models (LLMs) have received a huge amount of attention ever since ChatGPT first appeared at the end of 2022. ChatGPT represented a notable breakthrough in AI language models, surprising everyone with its ability to generate human-like text. However, it came with a notable limitation: the model could only be accessed via OpenAI’s servers. Users could interact with ChatGPT through a web interface, but they lacked access to the underlying architecture and model weights. Although a few months later OpenAI added access to the underlying GPT-3.5 model to its API, the models still resided on remote servers, and the underlying weights of the models couldn’t be changed. While this was necessary due to the model's enormous computational requirements, it naturally raised questions about privacy and access since all data could be read by OpenAI and an external internet connection was required.
Two years later and the situation has dramatically changed. Due to the rising availability of open-weights alternatives like Meta’s Llama models, we now have multiple options for running LLMs locally on our own hardware. Access is no longer tethered to cloud-based infrastructures.

- The transition from server-based LLMs like ChatGPT to locally runnable models, enabling customization and offline usage.
- The role of inference engines in executing neural networks using learned parameters for local model inference.
- Introduction to PagedAttention in vLLM, improving memory efficiency through better key-value cache management.
- A comparison of TGI and vLLM, highlighting shared features such as tensor parallelism and batching, and distinct features like speculative decoding and structured output guidance.
- Explanation of latency and throughput, including how these performance metrics influence LLM deployments.
- Advice on selecting between TGI and vLLM based on specific enterprise needs, focusing on use case experimentation and benchmarking.
- An overview of licensing differences, discussing TGI's shift back to Apache 2.0, aligning with vLLM’s license.
- Practical code examples showing how to deploy models using both TGI and vLLM for real-world applications.
What is an LLM inference engine?
At its most basic level, running a local model like Meta’s Llama 3.1 70B could involve two core files: the parameters file and a piece of code to execute those parameters. The parameters, also called the model’s “weights,” are the values that the model has learned during training. For instance, the Llama 3.1 70B model has 70 billion parameters, and each of these parameters is stored as a 2-byte value. This results in a parameter file that’s about 140 GB in size. This file is essentially a list of 70 billion values, and it is not executable on its own.
To actually run the model, you need a small piece of code—often written in C or Python (or a mix of both)—that defines how to interpret and use those weights to generate text. This code file, the inference engine, holds the neural network architecture and algorithm that process inputs and generate outputs based on the parameters.
Using just these two files—the parameters and the code—you can run the model directly on your local machine. You can compile the code, point it at the parameters file, and begin interacting with the model. For example, you could prompt it to generate a poem or an essay, just as you would with cloud-based models like ChatGPT.
Unlike proprietary models locked behind web interfaces, open-weights models allow for customization, experimentation, and offline usage, making it possible to run LLMs in entirely self-contained and private environments.
While the code to run these models can be extremely short, as in Andrej Karpathy's video, where he points to one that's a mere 500 lines, running a model as large as Llama 3.1 70B locally requires significant computational power.
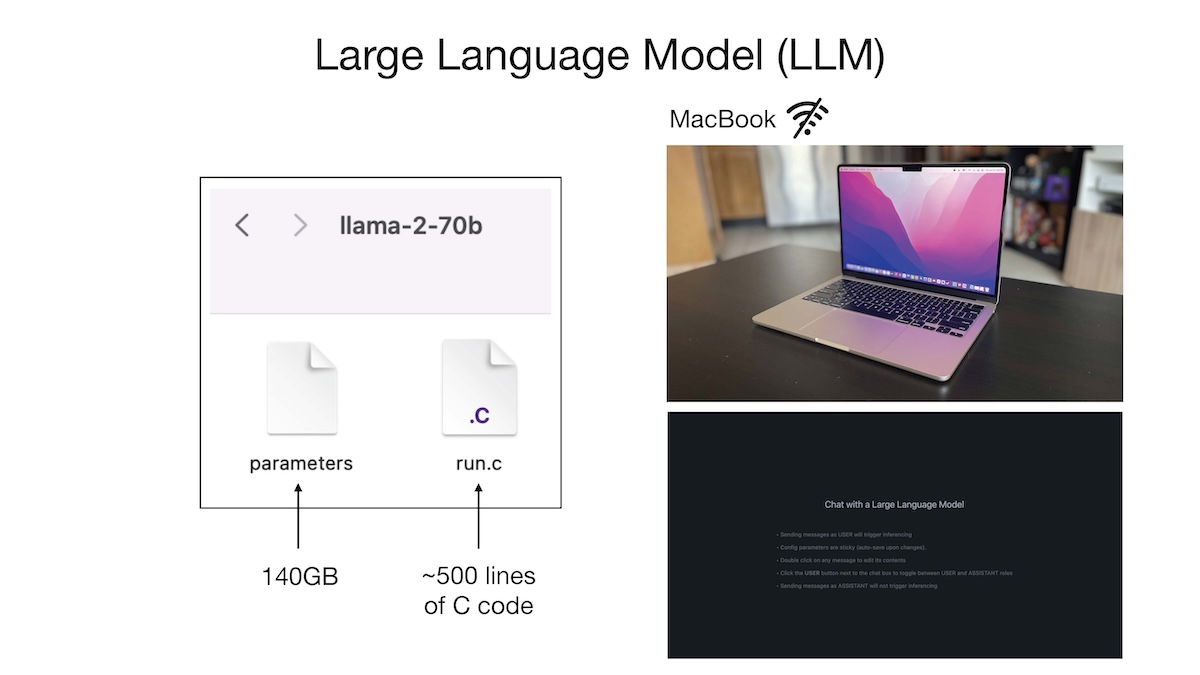
A model of that size in its raw format would need 140 GB of GPU memory to run at a realistically usable speed, and that could require two 80 GB GPUs costing tens of thousands of dollars. That’s not all they require: they need even more memory for activations, attention mechanisms, and intermediate computations. These requirements are only for a single user! For enterprise use, the model would need to serve many users concurrently, requiring a ton of GPUs for production-scale services. This is where robust LLM inference engines, such as vLLM and Hugging Face Text Generation Inference (TGI), become necessary.
vLLM and PagedAttention
A natural spot to start the discussion is with vLLM and the invention of PagedAttention, originally published in the paper “Efficient Memory Management for Large Language Model Serving with PagedAttention.”
PagedAttention solves the problem of inefficient memory management in LLM inference engines. LLMs are autoregressive, meaning the model predicts the next token in a sequence based on all the tokens that have come before it.

People images by OpenAI DALL-E 3. Text and comic bubbles by author.
Notice that when the woman asks her second question, she has to reiterate the entire previous conversation, complete with tags on who said what. LLMs require using their own outputs, plus the prompts that generated these outputs, to be prepended to the start of every new prompt from the user.
To do this efficiently, we need to cache certain values used to calculate self-attention scores so that the model isn’t recalculating the same things over and over. The KV cache (Key-Value cache) is a memory structure used in transformer models during the process of autoregressive text generation. It stores the intermediate states (keys and values) from previous tokens, which the model references when generating new tokens.
Traditional systems pre-allocate large, contiguous blocks of memory for the KV cache based on a maximum possible sequence length, even though many requests use much less memory. PagedAttention works by borrowing ideas from how operating systems manage virtual memory through paging. Instead of allocating a large contiguous block of memory for each request, it breaks the KV cache into smaller, fixed-sized blocks (or “pages”). These blocks are stored in non-contiguous memory locations.
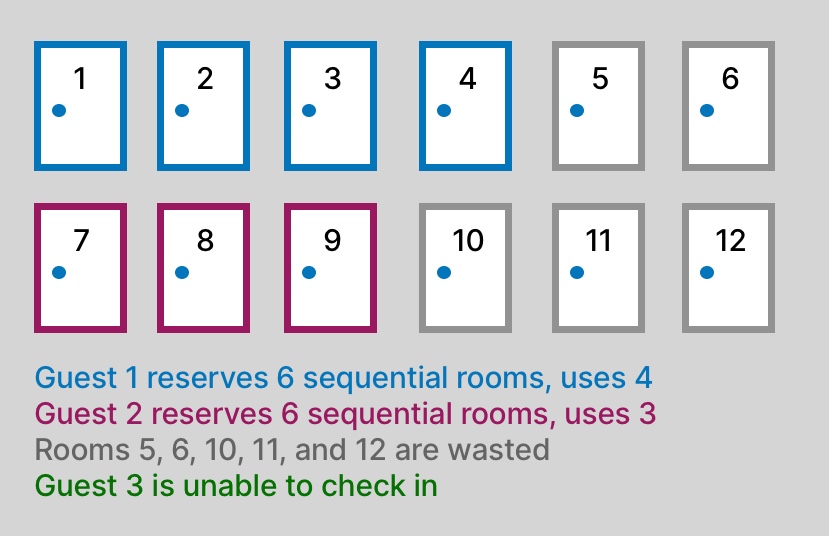
To understand how PagedAttention can solve this problem, imagine you’re managing a hotel with rooms, and each guest who checks in represents a token in a sequence that needs memory.
Contiguous Memory (Traditional Memory Allocation)
In this system, each guest has made a reservation for a certain number of hotel rooms for themselves and their friends, and the hotel management insists that every guest’s rooms must be placed next to each other in a straight line.
When the guest arrives, the hotel reserves one long row of adjacent rooms. This is acceptable if the guest knows exactly how many rooms they need, but they often don't—they have friends who either don't show or friends who bring other friends, so they end up needing fewer or more rooms than expected.
-
Problem 1: If you reserve 6 rooms but the guest only needs 4, the extra 2 rooms go unused (this is called internal fragmentation).
-
Problem 2: If another unexpected guest arrives but the remaining free rooms are scattered across different floors, you can’t check them in because the rooms aren’t in one long line. They’ll have to wait, even though you have enough rooms, but not in a contiguous block (this is called external fragmentation).
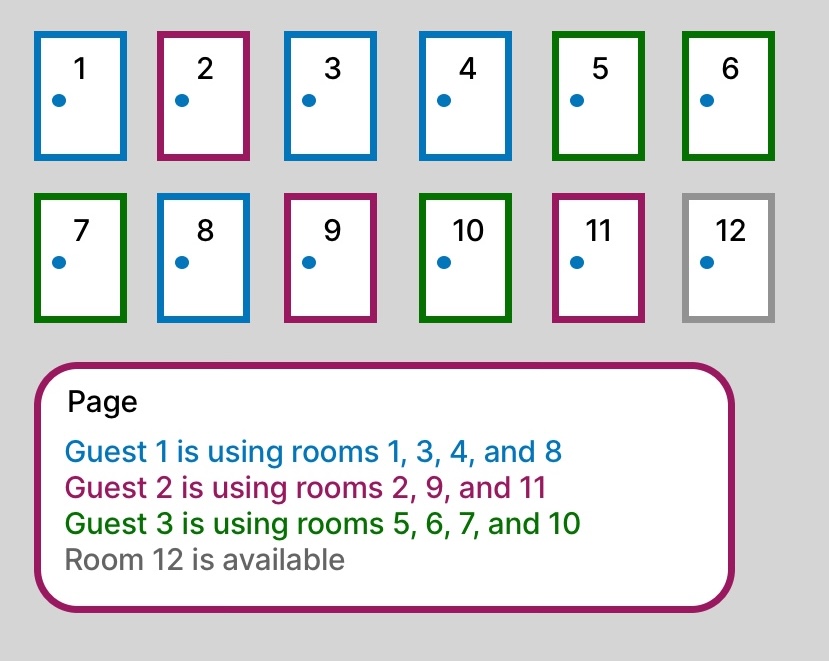
PagedAttention (Paged Memory Allocation)
Now you run the hotel like an apartment complex, where the rooms don’t need to be next to each other. Instead, guests can be accommodated in separate rooms throughout the building. Each guest is given a page in the hotel ledger that tracks where their rooms are located throughout the hotel. A guest needing 5 rooms can be allocated 2 rooms on one floor and 3 rooms on another. The hotel’s management keeps track of which rooms belong to which guest using the page.
This system avoids wasting rooms and allows more guests to check in.
-
Avoids Problem 1: No internal fragmentation. If a guest needs five rooms, they get exactly five, with no extra.
-
Avoids Problem 2: No external fragmentation: Guests don’t need to wait for a block of adjacent rooms to become available—they can take rooms anywhere. Without trying to fit all the rooms into one long line, you can fill in the gaps and maximize space.
There are also additional benefits to PagedAttention. Memory can be shared more efficiently between different processes or tasks, similar to how multiple guests could share a communal space instead of requiring separate ones.
How does vLLM compare to TGI?
When vLLM was first released, it outperformed TGI by a solid margin due to PagedAttention, performing with up to 2.2x to 3.5x higher throughput.
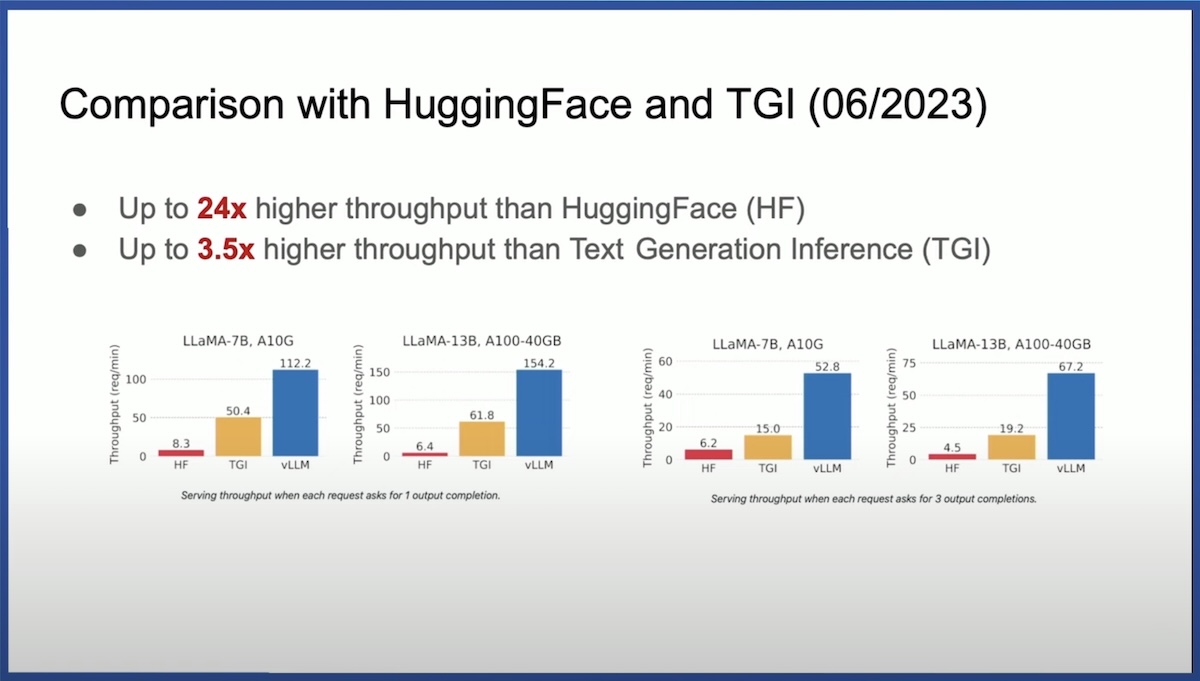
However, TGI soon incorporated PagedAttention, mentioning it in their GitHub repository in June 2023.
Currently, it’s quite tricky to make definitive statements about which inference engine is superior. LLM inference optimization is a rapidly evolving and heavily researched field; the best inference backend available today might quickly be surpassed by another as new optimizations become available.
Even more so, the web is becoming inundated—rather ironically—with LLM-generated garbage articles that frequently tout information that was already out-of-date when they were written. Even the product pages for vLLM and TGI themselves are not complete; when I was initially putting together the below table, I used TGI's and vLLM's GitHub readme files; however neither of them list all their supported quantizations. I had to check their respective documentation sites.
Nevertheless, you can clearly see that for many of these optimizations, the two engines are very similar.
Commonalities
| Feature | TGI | vLLM |
|---|---|---|
| Model Serving | Simple launcher to serve most popular LLMs | Seamless integration with Hugging Face models |
| Parallelism | Tensor parallelism for faster inference on multiple GPUs | Tensor and pipeline parallelism for distributed inference |
| Batching | Continuous batching of incoming requests for high throughput | Continuous batching of incoming requests for high throughput |
| Attention Optimization | Optimized transformers code with FlashAttention and Paged Attention | Efficient memory management with PagedAttention and FlashAttention |
| Quantization | GPTQ, AWQ, bitsandbytes, EETQ, Marlin, EXL2, and FP8 quantization | GPTQ, AWQ, bitsandbytes, Marlin, AQLM, DeepSpeedFP, GGUF, INT4, INT8, FP8 quantization |
| Streaming Outputs | Token streaming using Server-Sent Events (SSE) | Streaming outputs |
| Hardware Support | Supports NVIDIA, AMD, Intel, Google TPU, and AWS Trainium/Inferentia | Supports NVIDIA, AMD, Intel, PowerPC, TPU, and AWS Trainium/Inferentia |
| Multi-LoRA Support | Supports Multi-LoRA for adding multiple task-specific LoRA layers without retraining the model | Also supports Multi-LoRA for task-specific adaptation layers |
Unique features
This is where the engines diverge a bit, and we can more actively select the functionality we need.
-
When we want to reduce latency without compromising on the output's accuracy, speculative decoding becomes important. It does this by predicting the next tokens ahead of time, running speculative branches of the model in parallel and only finalizing the output once it’s clear which tokens are likely to be correct. This technique is especially useful in real-time applications like conversational agents, where every millisecond of delay matters.
-
Efficient beam search is useful in cases where high-quality output is necessary, but we also need to maintain scalability and performance. In applications like machine translation or summarization, beam search improves text coherence, and vLLM’s efficient beam search allows us to get high-quality outputs without sacrificing throughput. This makes it ideal for large-scale, enterprise-level deployments.
However, in scenarios where you need speed and low latency, such as in live chatbots or voice assistants, beam search may introduce delays. In these cases, simpler decoding strategies like greedy search or sampling might be preferred to ensure faster response times.
-
Watermarking is important when organizations need to ensure the traceability of AI-generated content, particularly in environments where content verification or intellectual property protection is a priority. Use cases such as legal document generation, journalism, and content moderation benefit from watermarking, which allows enterprises to ensure transparency while maintaining trust in the system’s integrity.
-
Prefix caching is important when dealing with repeated queries in chatbots, customer service automation, or document generation systems. In these cases, multiple requests often share similar prefixes or input sequences, and recalculating the same intermediate results for each query would waste computational resources. This can also be very helpful for RAG use cases, where a long document would be repeatedly used to answer questions.
| Feature | TGI | vLLM |
|---|---|---|
| Production Readiness | Distributed tracing with OpenTelemetry and metrics tracking with Prometheus | No emphasis on production monitoring, more focused on performance and throughput |
| Speculative Decoding | Not available | Supports speculative decoding for faster response time by predicting token generation |
| Guidance for Structured Output | Supports Guidance, enabling function calling and structured outputs based on schemas | No equivalent feature, focuses on flexible decoding algorithms like beam search |
| Watermarking | Includes A Watermark for Large Language Models to track model output | No watermarking feature available |
| Prefix Caching | Not available | Supports prefix caching to reduce latency for repeated queries |
So which engine is more performant?
To begin choosing which engine to use, we can note that TGI is well-suited for enterprises looking for production-ready deployments with robust monitoring and low-latency features such as token streaming and guidance for structured outputs. Its strong focus on observability and ease of deployment makes it ideal for applications requiring real-time interaction.
vLLM, on the other hand, is designed for enterprises focused on high-throughput serving of large models, with advanced memory management, broad quantization support, and superior distributed inference capabilities. It is particularly effective in multi-node and multi-GPU environments that demand maximum scalability and efficiency.
That said, there are still other factors, because when we talk about the performance of an LLM inference engine, there are multiple considerations.
Latency vs. Throughput
While these might sound like synonyms, they're actually orthogonal measurements.
When we say that latency and throughput are orthogonal measurements, it means they measure two independent aspects of system performance that don’t necessarily affect each other directly, and improving one does not automatically improve the other. However, system architecture often forces trade-offs between the two. When you optimize one, it can indirectly affect the other depending on how the system is designed.
- Latency is the time it takes to process and return a response to a single request (how fast the system responds to one user).
- Throughput is the number of requests or tokens the system can process per second (how much work it can handle in total).
While they are theoretically independent, in real-world systems, optimizing for one can affect the other. Minimizing latency for each request might reduce throughput because the system focuses on quickly responding to each user, possibly limiting how many users it can handle at once. Conversely, increasing throughput (handling more requests at once) might lead to higher latency per user because the system may batch requests or process them sequentially.
This video can help visualize this, showing that the LLM engine is producing 4 tokens per second; however, those are distributed among 4 users, so for each user it appears that it's only producing 1 token per second.
There are even more metrics to consider (the source again is Hugging Face)
| Term | Description |
|---|---|
| Token Latency | The amount of time it takes 1 token to be processed and sent to a user. |
| Request Latency | The amount of time it takes to fully respond to a request. |
| Time to First Token | The amount of time from the initial request to the first token returning to the user. This is a combination of the time to process the prefill input and a single generated token. |
| Throughput | The number of tokens the server can return in a set amount of time (e.g., 4 tokens per second). |
which leads to this useful table on what to emphasize:
| I care about… | I should focus on… |
|---|---|
| Handling more users | Maximizing Throughput |
| People not navigating away from my page/app | Minimizing Time to First Token (TTFT) |
| User Experience for a moderate amount of users | Minimizing Latency |
| Well-rounded experience | Capping latency and maximizing throughput |
Both TGI and vLLM offer benchmarking utilities, so the best course of action is to determine your use case and priorities, and experiment with both.
Licensing
vLLM has always used the Apache 2.0 license, a permissive open-source license that allows users to freely use, modify, and distribute software, provided they include proper attribution, a copy of the license, and a notice of changes, while also offering protection from patent claims.
TGI initially used the Apache 2.0 license, but then in July 2023, it changed its license from Apache 2.0 to the Hugging Face Optimized Inference License 1.0 (HFOILv1.0). This was widely disliked because it imposed the following restrictions on its previous Apache 2.0 license:
- No Hosting Services: You can’t offer the software as a paid online service without getting permission from Hugging Face.
- No Changing the License: You can’t relicense the software under different rules.
- Patent Clause: If you sue someone over patent issues related to the software, you lose the right to use it.
- Modification Requirements: If you change the software, you have to clearly state what changes you made and include that information when sharing it.
- No Use of Trademarks: You can’t use Hugging Face’s logos or trademarks without their approval.
In a video presentation from vLLM, you can hear the crowd's reaction when they point out that vLLM is still Apache 2.0 licensed.
Hugging Face later reverted back to Apache 2.0 in April 2024 so at this point their licensing is equivalent to vLLM. Both are open source software.
Brief code samples
For vLLM, the documentation is excellent and this code sample is taken directly from their quickstart.
vLLM
Installing vLLM
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.10 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllm
Consuming vLLM
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="facebook/opt-125m")
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
TGI
Launching TGI
TGI is distributed using Docker, so it's a bit different to set up, but also straightforward. You need to first install Docker and then proceed. Like vLLM above, this is taken verbatim from the TGI Quick Tour page.
model=teknium/OpenHermes-2.5-Mistral-7B
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data \
ghcr.io/huggingface/text-generation-inference:2.3.0 \
--model-id $model```
Consuming TGI (Python example)
Once TGI is running, you can use the generate endpoint or the Open AI Chat Completion API compatible Messages API by doing requests.
import requests
headers = {
"Content-Type": "application/json",
}
data = {
'inputs': 'What is Deep Learning?',
'parameters': {
'max_new_tokens': 20,
},
}
response = requests.post('http://127.0.0.1:8080/generate', headers=headers, json=data)
print(response.json())
# {'generated_text': '\n\nDeep Learning is a subset of Machine Learning that is concerned with the development of algorithms that can'}
Either vLLM or TGI will likely suit your needs
The best inference engine ultimately depends on your specific use case. Each engine offers distinct optimizations for different enterprise needs. TGI is great for real-time, production-ready applications with strong monitoring tools and structured output guidance, while vLLM shines in high-throughput environments with advanced memory management and distributed inference capabilities. The best way to decide is by experimenting and benchmarking each engine using the model and hardware specific to your workload, allowing you to tailor the solution to your priorities, whether that’s low latency, high throughput, or scalability.
And then do that every couple of months when everything changes again.

Generated with OpenAI DALL-E 3 and edited by the author.